"4:44

شاید برای شما هم پیش آمده باشد که با یک فایل PDF سنگین، یک کتاب آموزشی چندصد صفحهای یا جزوهای پر از نکات ریز روبرو شوید و نخواهید ساعتها صرف خواندن و خلاصهبرداری سنتی کنید. در دنیای امروز که سرعت حرف اول را میزند، یادگیری هم باید به همان نسبت سریع و هوشمند باشد. فرض کنید معلمی هستید که میخواهد بلافاصله بعد از تدریس از محتوای جزوهاش آزمون بگیرد، یا دانشجویی که قصد دارد میزان تسلطش را روی یک فصل خاص بسنجد. اینجاست که ترکیب هوش مصنوعی و کدنویسی به کمک ما میآید تا به جای صرف ساعتها وقت برای طرح سؤال، تنها با چند کلیک یک آزمون کامل و استاندارد داشته باشیم.
ساخت چنین ابزاری بیش از آنکه به دانش عمیق برنامهنویسی نیاز داشته باشد، به درک درست از نحوه تعامل با مدلهای زبانی بزرگ (LLM) و مدیریت دادهها بستگی دارد. در این مسیر، موضوعات زیر ستونهای اصلی توسعه ابزار شما خواهند بود:
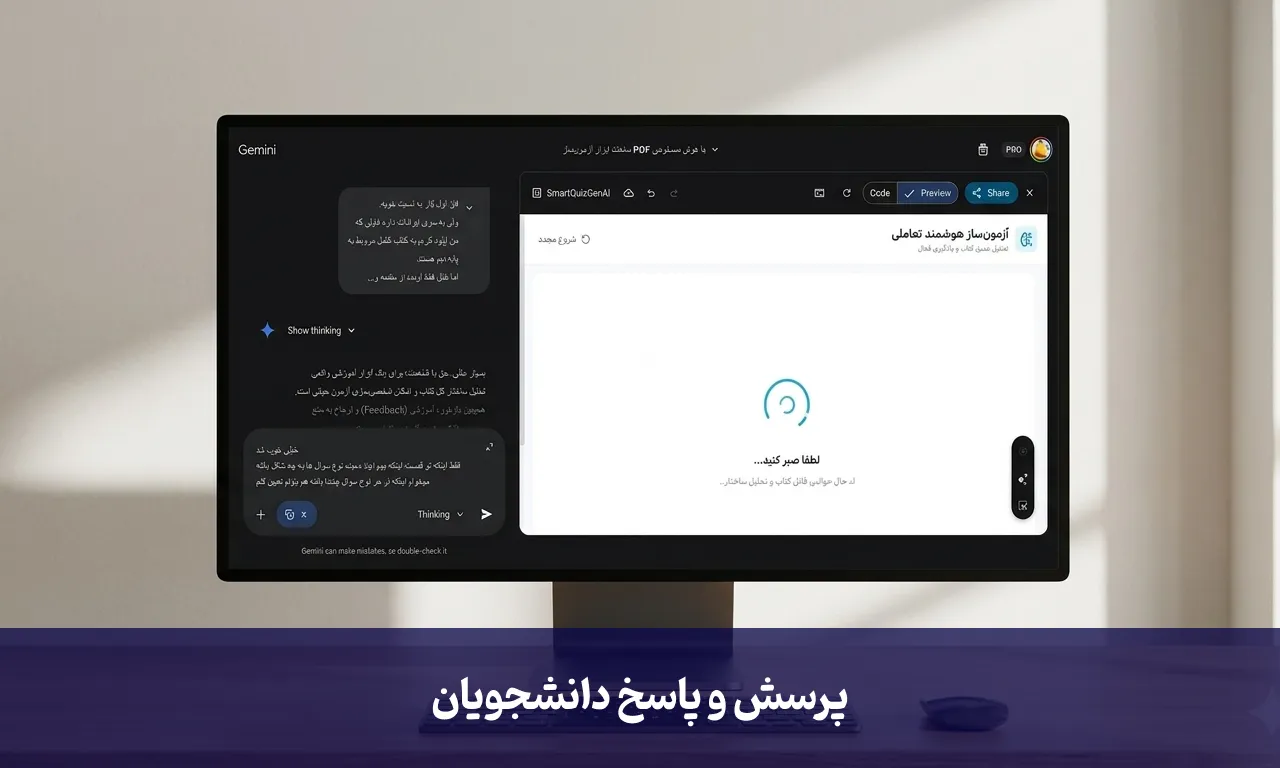
اولین قدم در ساخت یک آزمونساز هوشمند، استخراج درست اطلاعات است. شما فایلی را آپلود میکنید، اما هوش مصنوعی برای اینکه بتواند از دل آن سؤال طرح کند، نیاز به یک ساختار منظم دارد. اینجاست که مفهوم JSON اهمیت پیدا میکند. ما به هوش مصنوعی نمیگوییم «یک متن به من بده»؛ بلکه از او میخواهیم خروجی را در قالب یک «آرایه» منظم شامل سؤال، گزینهها و جواب درست به ما تحویل دهد. با این روش، سیستم شما بهصورت خودکار متوجه میشود که کدام بخش را بهعنوان صورت سؤال نمایش دهد و کدام را برای تصحیح آزمون در حافظهاش نگه دارد.
گاهی اوقات ممکن است در این مسیر با خطاهایی مثل “Unexpected Token” روبرو شوید. این موضوع معمولاً زمانی رخ میدهد که حجم خروجی درخواستی شما از حد مجاز (Limit) مدل فراتر میرود. در مدلهای رایگان، محدودیتهایی در میزان توکنهای خروجی وجود دارد. برای حل این مشکل، یا باید درخواستها را خرد کرد و یا به سراغ مدلهای سبکتر و بهینهتری مثل Gemini 2.5 Flash رفت که سرعت بالاتر و محدودیتهای منعطفتری دارند.
یکی از جذابترین و در عین حال چالشبرانگیزترین بخشها، کار با فایلهایی است که لزوماً متنِ قابل انتخاب (Selectable) ندارند. برای مثال، جزوههای دستنویس یا PDFهایی که در واقع مجموعهای از تصاویر هستند. در اینجا دو راه پیش روی ماست: استفاده از کتابخانههای سمت فرانتاِند مثل pdf.js برای استخراج متن، یا سپردن کل کار به خودِ مدل هوش مصنوعی.
تجربه نشان داده است که برای محتوای فارسی، به خصوص زمانی که فونتهای خاص یا جداول پیچیده در کار باشد، فرستادن مستقیم فایل برای مدلهای پیشرفتهای مثل جمینای (Gemini) نتیجه بسیار دقیقتری دارد. این مدلها به دلیل قابلیتهای مالتیمودال (Multimodal)، تصویر را میبینند، تحلیل میکنند و محتوا را با دقت بالاتری نسبت به اوسیآرهای (OCR) معمولی درک میکنند.
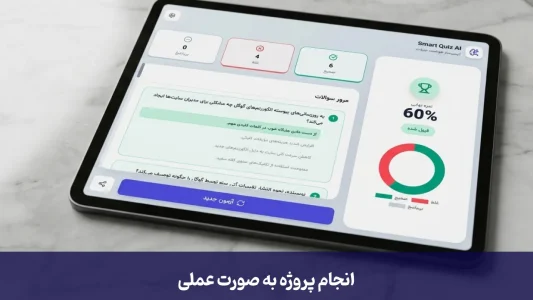
یک ابزار کاربردی نباید فقط به طرح چند سؤال تصادفی بسنده کند. شما میتوانید با اضافه کردن چند لایه منطقی، سطح آزمون را کنترل کنید. مثلاً به کاربر اجازه دهید تعیین کند که آزمون در سطح «آسان، متوسط یا سخت» باشد، یا حتی تعداد سؤالات را خودش انتخاب کند. حتی میتوان پا را فراتر گذاشت؛ به جای اینکه فقط سؤالات چهارگزینهای داشته باشیم، از هوش مصنوعی بخواهیم سؤالات جایخالی یا صحیحوغلط طراحی کند تا یادگیری عمیقتر شود.
یکی از کاربردهای واقعی این سیستم در سایتهای آموزشی بزرگ است. تصور کنید صدها مقاله در سایت دارید و میخواهید برای هر کدام یک آزمون سنجش یادگیری بسازید. به جای استخدام تیم تولید محتوا برای ماهها کار مداوم، میتوان اسکریپتی نوشت که تمام مقالات را بخواند، آزمونها را طراحی کند و در دیتابیس ذخیره کند. کاری که ماهها زمان میبرد، در کمتر از یک روز با دقت بالا انجام میشود.
در نهایت، ساخت ابزار با هوش مصنوعی یک فرآیند آزمون و خطای لذتبخش است. از نمایش نمره نهایی گرفته تا ارائه پاسخهای تشریحی و حتی ارجاع کاربر به صفحه خاصی از کتاب برای مطالعه بیشتر، همگی امکاناتی هستند که ابزار شما را از یک پروژه ساده به یک دستیار آموزشی حرفهای تبدیل میکنند. مهم این است که از مواجهه با خطاهای API یا کدهای پیچیده نترسید؛ چرا که هر خطا، راهنمایی برای بهینهتر کردن ابزار شماست. با کمی خلاقیت در طراحی رابط کاربری و استفاده درست از قدرت پردازش مدلهای زبانی، میتوانید پلتفرمی بسازید که یادگیری را برای هر کسی، در هر سطحی، ساده و لذتبخش کند.