"52:28

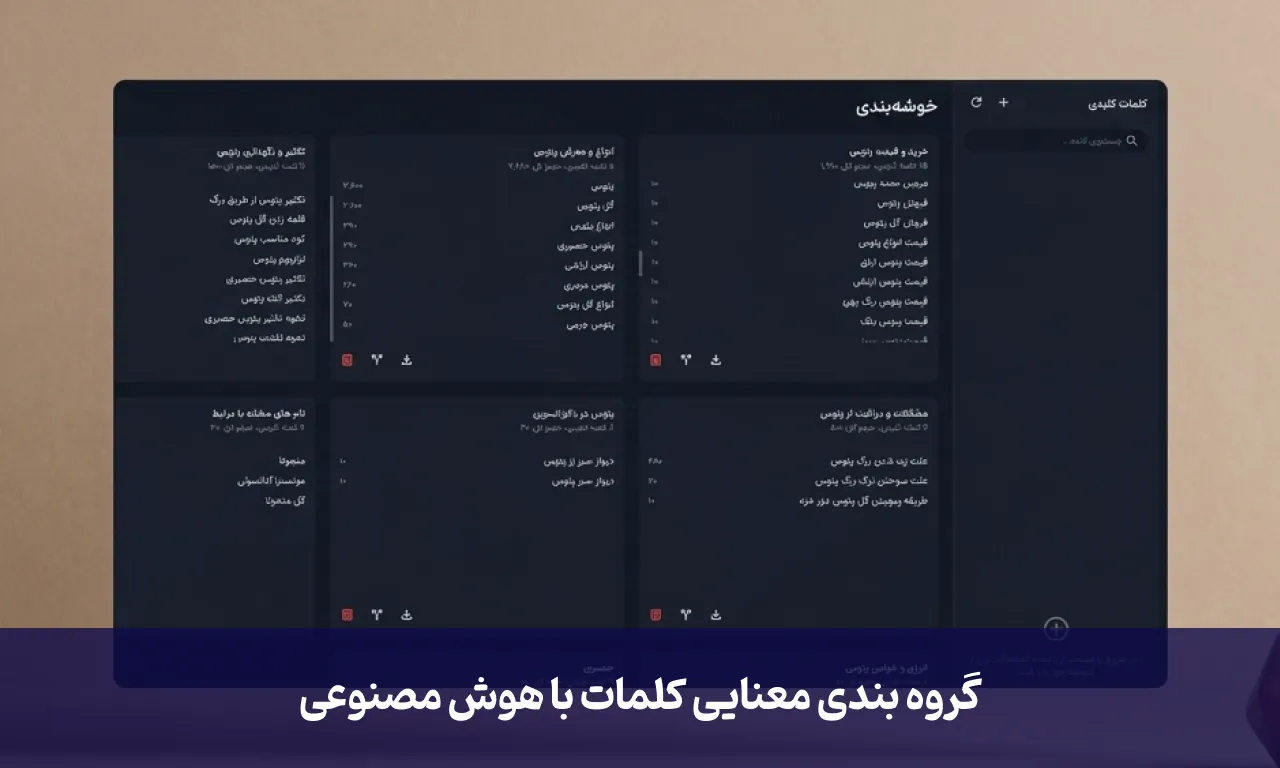
وقتی لیست کلمات کلیدی یک پروژه سئو از چند ده تا به چند هزار کلمه میرسد، دیگر دستهبندی دستی و چشمی آنها نه منطقی است و نه امکانپذیر. از طرفی، ابزارهای خارجی هم هزینههای اشتراک دلاری و محدودیتهای خاص خودشان را دارند. راهکار جایگزین چیست؟ اینکه خودمان دست به کار شویم و یک ابزار اختصاصی بسازیم.
توسعه نرمافزار به کمک هوش مصنوعی (Vibe Coding) این قدرت را به ما میدهد که ایدههای پیچیده را سریعتر از همیشه به محصول تبدیل کنیم. ما میتوانیم از مدلهای هوشمند کمک بگیریم تا کلمات را بر اساس مفهوم و کاربردشان خوشهبندی (Clustering) کنند. اما ساخت یک ابزار واقعی، فقط کپیپیست کردن کدهای تولید شده توسط جمنای یا سایر چتباتها نیست؛ بلکه نیازمند مدیریت منابع، درک محدودیتهای API و حل چالشهای منطقی برنامه است.
در این مسیر توسعه، با مفاهیم و چالشهای مختلفی دستوپنج نرم میکنیم تا به یک محصول باثبات برسیم:
وقتی یک بخش از برنامه (مثل سیستم حساب کاربری، دیتابیس و اتصال درگاه پرداخت) به ثبات میرسد، هیجانِ اضافه کردن فیچرهای جدید نباید باعث شود منطق نسخه اصلی را به خطر بیندازیم. کدهای فرانتاند و بکاند (مثل فایلهای Worker) با اضافه شدن هر قابلیت جدید، به سرعت طولانی و پیچیده میشوند.
قبل از اینکه به سراغ یک تغییر ساختاری مثل سیستم خوشهبندی برویم، ساختن یک «برنچ» جدید یا حتی یک کپی ساده آفلاین از فایلهای HTML و JS، ما را از کابوسِ از دست رفتن کدهای سالم نجات میدهد. این یک عادت حرفهای است: وقتی کد بدون مشکل کار میکند، آن را فریز کن و توسعه را روی یک نسخه جدید پیش ببر تا اگر هوش مصنوعی در خروجی جدیدش کدهای قبلی را خراب کرد، راه برگشت داشته باشی.
یکی از اشتباهات رایج در کار با APIهای هوش مصنوعی، ارسال حجم عظیمی از داده در یک درخواست (Request) است. ما نمیتوانیم چند هزار کلمه کلیدی را یکجا به مدل بدهیم و انتظار داشته باشیم همه آنها را با دقت تفکیک کرده و در کلاسترهای درست نمایش دهد. محدودیتهای توکن (Token Limits) و هزینههای هر درخواست، ما را مجبور میکند هوشمندانه و بهینهتر عمل کنیم.
برای حل این مشکل، منطق ادغام (Merge) و انتخاب گزینشی را پیادهسازی میکنیم. در رابط کاربری ابزار، امکانی فراهم میشود تا کاربر کلمات مربوط به چند موضوع مختلف (مثلاً «پتوس» و «سانسوریا») را از تاریخچه خود انتخاب کند. در این مرحله، سیستم باید کلمات تکراری را حذف کند تا دیتای تمیزتر و کمحجمتری برای پردازش به سمت جمنای ارسال شود. نمایش مجموع کلمات و حجم جستجوی آنها قبل از پردازش، به ما کمک میکند درک بهتری از دیتای ورودی داشته باشیم.
دوگانه جاوا اسکریپت و هوش مصنوعی در خوشهبندی خوشهبندی همیشه نیازمند پردازشهای سنگین و معنایی نیست. ما در این ابزار برای ایجاد کلاسترها دو مسیر کاملاً مجزا را پیش پای کاربر میگذاریم:
در مسیر توسعه بخش هوش مصنوعی، انتخاب مدل (Model Selection) اهمیت حیاتی پیدا میکند. مدلهای پیشنمایش یا سنگین (مثل نسخههای Pro یا Preview) شاید دقیق باشند، اما پردازش کلاسترها را کند کرده و هزینه نگهداری ابزار را بالا میبرند. با تغییر استراتژی و سوئیچ کردن کدهای Worker روی مدلهای سبکتر و سریعتر (مثل مدلهای Flash یا Flash-Lite)، سرعت پاسخگویی ابزار به شکل چشمگیری افزایش پیدا میکند، بدون اینکه افت کیفیت محسوسی در خوشهبندی کلمات داشته باشیم.
کدنویسی با هوش مصنوعی یک مسیر خطی و بدون باگ نیست. گاهی جمنای صدها خط کد تولید میکند، اما یک کلاس CSS ساده را برای نمایش مُدال (پاپآپ) جا میاندازد و باعث میشود دکمهها اصلاً کار نکنند! یا ممکن است در یک حلقه تکرار (Loop) بیفتد و کلاسترهای خالی و اضافه تولید کند.
در این مواقع، نقش ما به عنوان یک «هدایتگر» مشخص میشود. ما باید کنسول مرورگر را بررسی کنیم، باگهای منطقی (مثل حذف شدن اشتباه کلمات اصلی هنگام تقسیمبندی مجدد یک خوشه) را پیدا کنیم، مشکلات رابط کاربری (مثل عدم نمایش لودینگ در زمان انتظار برای پاسخ API) را شناسایی کنیم و قدمبهقدم از هوش مصنوعی بخواهیم تا فایلها را اصلاح کند. این رفتوبرگشتها بخش طبیعی و جداییناپذیر ساخت یک محصول واقعی است.
با عبور از این چالشها، ما موفق میشویم ابزاری بسازیم که نهتنها کلمات را بهخوبی خوشهبندی میکند، بلکه مجموع حجم جستجوها را در هر دسته نشان میدهد و امکان دانلود خروجی منظم (فایل CSV مرتبشده بر اساس میزان سرچ از زیاد به کم) را فراهم میکند. خروجی نهایی، یک کیورد پلنر کاملاً شخصیسازیشده است که مشابه ابزارهای گرانقیمت بازار عمل میکند، اما صفر تا صد آن تحت کنترل خودمان قرار دارد.
ساخت این ابزار نقطه پایان نیست. رفع باگهای بصری باقیمانده، توسعه پنل ادمین برای مدیریت کاربران و بررسی میزان مصرف، و همچنین ایجاد دسترسی به کلمات دمدرازتر (Long-tail) از قدمهای جذابی است که در آینده میتوان به این پروژه اضافه کرد. مهمترین دستاورد این مسیر، درک این حقیقت است که با ترکیب شناخت درست از منطق برنامهنویسی و هدایت اصولی هوش مصنوعی، میتوانیم قدرتمندترین ابزارهای اختصاصی را برای نیازهای خودمان بسازیم.