"19:42

آیا تا به حال به این فکر کردهاید که چطور میتوان از انبوه نظرات و سوالات کاربران در سایتهایی مثل دیجیکالا، مهمترین اطلاعات را استخراج و تحلیل کرد؟
وقتی در حال گشتوگذار در یک فروشگاه اینترنتی بزرگ مثل دیجیکالا هستید؛ همه چیز ساده به نظر میرسد: روی یک محصول کلیک میکنید، عکسها باز میشوند، قیمت را چک میکنید و شاید سری هم به بخش نظرات بزنید. اما پشت این ظاهر آرام و چیدمان مرتب، یک ترافیک سنگین و مهندسیشده از دادهها در جریان است. هر حرکت شما، از باز کردن یک صفحه تا کلیک روی دکمه «مشاهده همه پرسشها»، جرقهای است که یک درخواست (Request) به سمت سرور میفرستد تا تکهای از اطلاعات را برای شما بیاورد.
بسیاری از ما وقتی میخواهیم دیتای یک سایت را برای تحلیلهای هوش مصنوعی یا پروژههای شخصی استخراج کنیم، به فکر روشهای پیچیده میافتیم، در حالی که بخش بزرگی از این گنجینه، درست جلوی چشمان ما و در تب Network مرورگرمان قرار دارد. چالش اصلی اینجاست که چطور این دادههای خام را پیدا کنیم، آنها را از حصار محدودیتها عبور دهیم و در نهایت به شکلی درآوریم که برای مدلهای هوش مصنوعی قابل فهم باشد.
در این مسیر، قرار است با مفاهیم و ابزارهای زیر دستوپنجه نرم کنیم:
وقتی به عنوان یک متخصص هوش مصنوعی یا برنامهنویس به یک صفحه وب نگاه میکنید، باید دیدی فراتر از یک کاربر معمولی داشته باشید. ابزار Inspect مرورگر، پنجرهای رو به دنیای زیرین سایت است. بخش Network، جایی است که تمام گفتگوهای مخفیانه بین مرورگر شما و سرور دیجیکالا ثبت میشود.
وقتی صفحه را رفرش میکنید، لیستی طولانی از فایلها ظاهر میشود. اما برای ما، جذابترین بخش، درخواستهای XHR یا Fetch هستند. اینها همان درخواستهایی هستند که دیتای خالص را، بدون هیچ زرق و برق گرافیکی، به فرمت JSON حمل میکنند. مثلاً با کمی جستوجو، به درخواستی برمیخورید که شامل ID محصول است. وقتی پاسخ (Response) این درخواست را باز میکنید، میبینید که تمام جزئیات، از دسکریپشن محصول گرفته تا وضعیت فروشنده، به صورت مرتب چیده شدهاند.
سایتهای مدرن برای سرعت بیشتر و مصرف بهینه اینترنت، همه اطلاعات را یکباره بارگذاری نمیکنند. چرا باید دیتای هزاران پرسش و پاسخ لود شود، در حالی که شاید کاربر اصلاً به پایین صفحه نرود؟ اینجاست که مفهوم بارگذاری بر اساس رفتار (Event-driven loading) اهمیت پیدا میکند.
تا زمانی که شما روی تب «پرسش و پاسخ» کلیک نکنید، درخواستی برای گرفتن آن دیتا ارسال نمیشود. اما به محض کلیک، یک End-point جدید در کنسول ظاهر میشود که تمام سوالات و جوابها را در خود دارد. این یک فرصت طلایی برای ماست؛ یعنی میتوانیم دقیقاً متوجه شویم که برای دریافت هر بخش از اطلاعات، باید به کدام آدرس مراجعه کنیم.
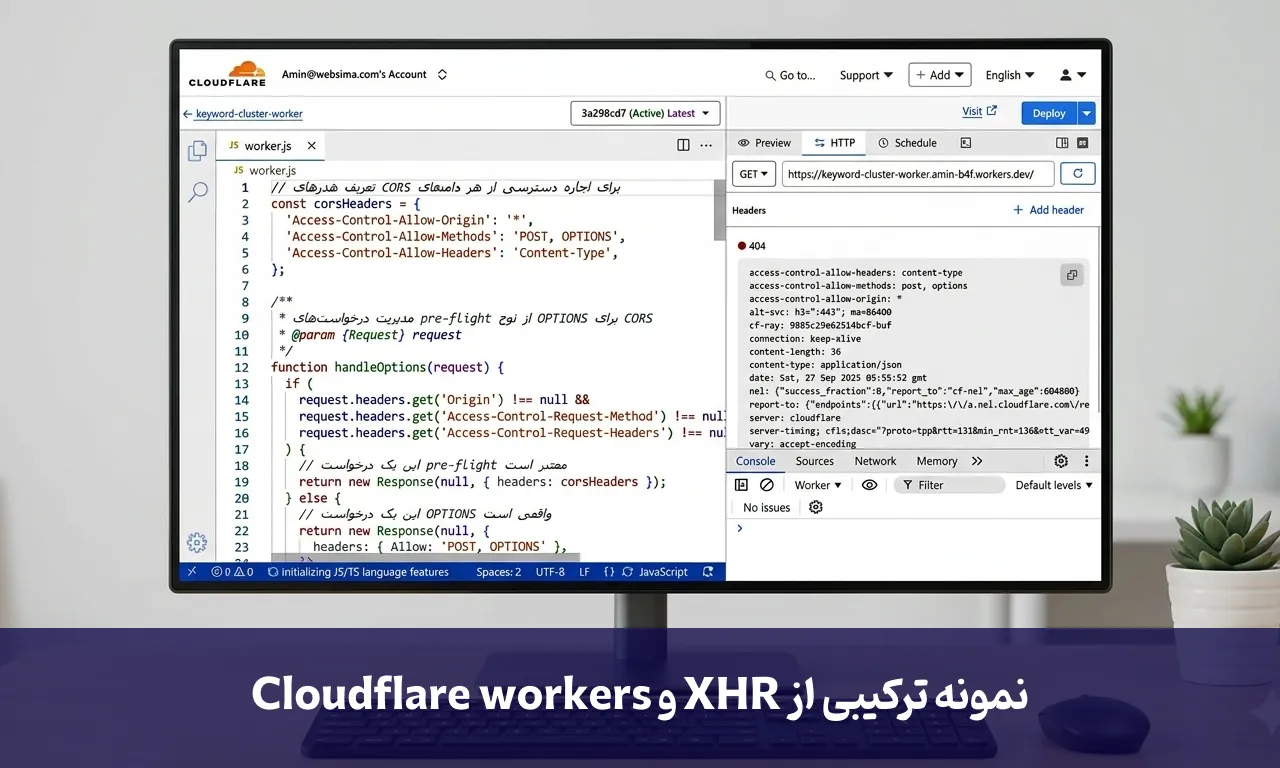
پیدا کردن آدرس دیتا قدم اول است، اما همیشه همهچیز به همین سادگی پیش نمیرود. گاهی سایتها محدودیتهایی برای دسترسی مستقیم قائل میشوند یا ما نیاز داریم دادهها را قبل از رسیدن به مقصد نهایی، کمی تغییر دهیم یا فیلتر کنیم. اینجا همان جایی است که Cloudflare Workers وارد بازی میشود.
تصور کنید میخواهید یک ربات یا ابزار هوشمند بسازید که قیمتها را مانیتور کند یا نظرات را تحلیل کند. به جای اینکه یک سرور سنگین و گرانقیمت اجاره کنید، میتوانید از این سرویس استفاده کنید. این ابزار مانند یک کارگر چابک در لبه شبکه (Edge) قرار میگیرد، درخواست شما را میگیرد، به سمت مقصد میفرستد و نتیجه را به شکلی که شما دوست دارید (مثلاً فقط متن نظرات، بدون کدهای اضافی) برمیگرداند.
هدف نهایی ما فقط دیدن این کدها نیست. ما میخواهیم این دادهها را به خوراک مناسبی برای مدلهای زبانی بزرگ (LLM) تبدیل کنیم. وقتی شما یاد بگیرید چطور خروجیهای تمیز JSON را از دل سایتهای بزرگی مثل دیجیکالا بیرون بکشید، عملاً مانع «کمبود داده» را از سر راه پروژههای هوش مصنوعی خود برداشتهاید.
در واقع، شما با یادگیری این تکنیکها، یاد میگیرید که چطور ساختار یک سایت را تحلیل کنید، رفتارهای داینامیک آن را بفهمید و در نهایت با ابزارهای مدرنی مثل Cloudflare، یک سیستم انتقال داده پایدار بسازید. این مهارتی است که مرز بین یک توسعهدهنده معمولی و کسی که میتواند پروژههای واقعی و دیتامحور هوش مصنوعی را مدیریت کند، تعیین میکند.
مسیر یادگیری ما از یک کلیک ساده در کنسول مرورگر شروع شده و به نوشتن کدهای بهینه در محیطهای Serverless ختم میشود؛ مسیری که در آن یاد میگیرید چگونه هوشمندانه از منابع موجود در وب برای خلق ارزشهای جدید استفاده کنید. ترغیب به درک عمیقتر این فرآیند، اولین قدم برای ورود به دنیای حرفهای مهندسی داده و هوش مصنوعی است.