فایل Robots.txt چیست؟ تابلو ورود ممنوع برای رباتهای گوگل
رباتهای گوگل به صورت شبانهروزی در حال بررسی وب هستند و همه صفحات برای آنها قابل ایندکس است، مگر اینکه دسترسی رباتهای گوگل توسط مدیر سایت به یک یا چند صفحه مسدود شده باشد. یکی از بهترین روشها برای این کار استفاده از فایل robots.txt است
- رباتهای سرگردان؛ لطفاً وارد این صفحه نشوید!
- یک مثال برای درک بهتر اهمیت Robots.txt
- چه زمانی لازم نیست محدودیتی برای گوگل در نظر بگیریم؟
- آموزش ساخت فایل Robots.txt + ویدیو
- گام آخر؛ تست آنلاین عملکرد فایل robots.txt
- وقتی گوگل به حرف دستورات ما اهمیتی نمیدهد!
- بررسی فایل Robots.txt در دیجی کالا و آپارات
- قوانین فقط برای رباتهای گوگل هستند؟ برای سایر ابزارها چه کار کنیم؟
- فایل Robots.txt تنها ابزار مدیریت بودجه خزش نیست
- رایجترین سوالات در مورد فایل robots.txt
در طی یک ماه گوگل بیش از 30 هزار بار صفحات سایت آکادمی وبسیما را بررسی کرده و نزدیک به 1 گیگابایت از پهنای باند ما را مصرف کرده است! حالا تصور کنید که این عددها برای یک سایت خبری یا فروشگاهی اینترنتی بزرگ چند برابر خواهد بود؟
درست متوجه شدید، رباتهای گوگل همچون کاربران عادی از منابع هاست و سرور ما استفاده میکنند. شاید تصور کنید که پهنای باند سایت آنقدر زیاد هست که بتواند پاسخگوی این نیاز باشد اما این همه ماجرا نیست. بودجه خزش فقط محدود به منابع سرور ما نیست بلکه برای گوگل نیز اهمیت زیادی داشته و برای هر سایتی متفاوت است. به عبارت دیگر؛
بودجهای که گوگل برای بررسی سایت و ایندکس صفحات در نظر میگیرد یکی از منابع محدود و بسیار ارزشمند برای ما است.
صفحات زیادی در سایت ما هستند که از منظر سئو هدف یا ارزش خاصی ندارند. بررسی مداوم این صفحات موجب میشود تا بودجه خزش سایت ما بیهدف مصرف شده و محتوایی که دوست داریم سریعتر در صفحه نتایج جستجو دیده شود با تاخیر بسیار زیادی ایندکس میشود.
اما چه راهی وجود دارد تا به رباتهای گوگل بگوییم که شما حق ورود به این صفحات را ندارید؟ بهترین راه استفاده از فایل Robots.txt است. برای درک بهتر این مفاهیم بهتر است که پیش از هر چیز بودجه خزش را بهدرستی درک کنیم، اگر با این مفهوم آشنا نیستید پیشنهاد میکنیم مقاله بودجه خزش را در آکادمی وبسیما مطالعه کنید.
به عبارت دیگر فایل Robots.txt مثل یک تابلو ورود ممنوع عمل کرده و از گردش بیهوده رباتهای گوگل در صفحات وب جلوگیری میکند. فکر میکنم تا همینجا به اهمیت و ارزش آن در سئو پی برده باشید، اصلا نگران نباشید، در این مقاله ابتدا تعریف دقیقی از کاربرد این فایل ارائه میکنیم و در ادامه نحوه ساخت و مدیریت آن به گوگل را میآموزیم.
آهای رباتهای سرگردان؛ لطفاً وارد این صفحه نشوید!
زمانیکه ربات گوگل وارد سایت ما میشود پیش از هر چیز نیمنگاهی با فایل robots.txt خواهد داشت. بررسی این فایل به ربات گوگل کمک میکند تا تشخیص دهد که آیا اجازه دسترسی به صفحه مورد نظر را دارد یا خیر؟
هر سایتی ساختار و ظاهر متفاوتی دارد، رباتها چطور انقدر سریع و راحت به فایل مورد نظر دسترسی دارند؟ جواب این سوال ساده است؛ گوگل برای ساخت و مدیریت این فایل چند قانون ساده در نظر گرفته تا دسترسی به آن در همه سایتها ساده باشد. قوانین گوگل عبارتند از:
- نام فایل robots.txt باشد (به حروف کوچک دقت کنید).
- در سایت خودمان بارگذاری شده باشد و بلافاصله بعد از نام دامنه در دسترس باشد (مثلا websima.academy/robots.txt را بررسی کنید).
- محتوا و فرمت فایل txt باشد تا دسترسی و خوانایی آن برای رباتها ساده باشد.
با همین قوانین ساده متوجه میشویم که؛ اگر در انتهای نام هر دامنهای robots.txt/ را بنویسیم بهراحتی میتوانیم محتوای فایل و قوانین درج شده را در آن مشاهده کنیم.
برای درک بهتر مفهوم و آشنایی با عملکرد فایل robots.txt پیشنهاد میکنیم ویدیوی کوتاه زیر (کمتر از 3 دقیقه) را مشاهده کنید.
یک مثال برای درک بهتر اهمیت Robots.txt
همه افرادی که در سایت آکادمی وبسیما و در یکی از دورههای آموزشی ثبتنام میکنند یک صفحه پروفایل اختصاصی با آدرس یکتا و به نام خودشان خواهند داشت. در این صفحه مسیر یادگیری خود و نظرات درج شده را مشاهده کرده و اجازه دارند مشخصات خود مثل راههای تماس و رزومهای کوتاه را درج کنند.
تاکنون بیش از 2000 صفحه پروفایل کاربری بر روی سایت آکادمی وبسیما ایجاد شده است. در مقابل تعداد صفحات مرتبط با مقالات و دورههای آموزشی کمتر از 300 آدرس یکتا است. صفحات پروفایل کاربران هیچ نقشی در استراتژی سئو آکادمی وبسیما ندارند. به عبارت دیگر، گردش رباتهای گوگل در این صفحات تنها بودجه خزش را به هدر میدهد.
دقت کنید که صفحات ارزشمند سایت ما تنها یک بار توسط گوگل بررسی و ایندکس نمیشوند بلکه رباتهای گوگل به صورت مستمر این آدرسها را بررسی (Crawl) کرده و تغییرات هرکدام مانند اضافه شدن محتوای جدید یا درج دیدگاه توسط کاربران را رصد میکنند.

به عنوان مثال صفحه سئو چیست در سایت ما محتوایی مشخص و ثابت دارد که بهندرت تغییر خواهد کرد ولی ثبت نظرات جدید توسط کاربران در این صفحه موجب میشود تا محتوای آن چندین بار در طول ماه بهروزرسانی شود. به نظر شما زمان رباتهای گوگل بهتر است صرف بررسی کدام صفحه شود؟ 2000 پروفایل کاربری یا 300 صفحه با محتوای ارزشمند؟
تا اینجا با مفهوم و کاربرد این فایل آشنا شدیم و احتمالا از سر کنجکاوی محتوای آن را در سایت خودتان یا سایتهای معتبری که از آنها استفاده میکنید، بررسی کردهاید. قبل از آنکه در مورد نحوه ساخت و مدیریت فایل robots.txt صحبت کنیم باید این نکته را یادآور شویم که؛
داشتن فایل robots.txt برای همه سایتها ضروری نیست و تاثیر مستقیم بر رتبهبندی در نتایج جستجو ندارد!
چه زمانی لازم نیست محدودیتی برای گوگل در نظر بگیریم؟
اگر تعداد صفحات سایت ما بسیار کم باشد (مثلا کمتر از 100 صفحه یکتا داشته باشیم) و همه آنها با هدف سئو منتشر شده باشند، نیازی به ساخت و مدیریت فایل robots.txt نداریم. البته در دنیای امروز سایتهای کمی هستند که چنین شرایطی داشته باشند.
در سایتهایی که آدرسدهی صفحات به صورت خودکار انجام شده و ممکن است هزاران مسیر مختلف برای دسترسی به یک صفحه وجود داشته باشد استفاده از این فایل ضروری است.
بهعنوان مثال یک فروشگاه اینترنتی را در نظر بگیرید که با استفاده از فیلترهای متعدد دسترسی به محصول و جستجو را برای کاربران ساده کرده است. با انتخاب هر فیلتر آدرس صفحه تغییر میکند ولی محتوای ارزشمند و متفاوتی به کاربر ارائه نمیشود. بررسی و ایندکس همه این آدرسها توسط گوگل نهتنها بودجه خزش سایت را بیهوده مصرف میکند بلکه ممکن است مشکلات بزرگتری مانند کنیبالیزیشن را در سایت ما ایجاد کند.
اگر با مفهوم Cannibalization و تاثیر آن بر سئو آشنا نیستید پیشنهاد میکنیم در فرصتی مناسب مقاله کنیبالیزیشن چیست را مطالعه کنید.
بیش از این شما را منتظر نمیگذاریم، در ادامه روش ساخت فایل robots.txt و قوانین حاکم بر آن را با هم مرور میکنیم.
آموزش ساخت فایل Robots.txt + ویدیو
ساخت فایل Robots.txt بسیار ساده است. یک فایل متنی با فرمت txt ایجاد کنید و دستورات مورد نظر خود را در آن بنویسید. در نهایت این فایل را در ریشه اصلی هاست خود آپلود کرده و مطمئن شوید که با وارد کردن آدرس آن در انتهای نام دامنه در دسترس باشد.
برای مدیریت این فایل باید قواعد و قوانین حاکم بر آن را به درستی بشناسیم، در این فایل سه قاعده اصلی وجود دارد که در ادامه کاربرد هرکدام را معرفی میکنیم:
User-agent: مشخص میکند که دقیقا چه رباتی نباید به صفحه مورد نظر دسترسی داشته باشد. با قراردادن کاراکتر * دسترسی هر نوع رباتی را محدود میکنیم.
Disallow: آدرس صفحه، فایل، دایرکتوری یا تصویری که رباتهای گوگل اجازه دسترسی به آن را ندارند مشخص میکند.
Allow: اگر بخواهیم آدرس مشخصی را برای گوگل قابل دسترس کنیم در حالی که دایرکتوری مادر آن از دسترس گوگل خارج شده است، از این دستور استفاده میکنیم. در حقیقت استفاده از Allow به عنوان یک شرط عمل میکند.
حدس می زنیم کمی گیج شدهاید، حق هم دارید! با توضیحات متنی نمیتوان کاربرد هریک از این قواعد و موارد استفاده از آنها را بهخوبی توضیح داد.
پیشنهاد میکنیم ویدیوی زیر را به دقت مشاهده کنید، طی 10 دقیقه و با بررسی مثالهای متعدد نحوه استفاده صحیح از این دستورات را آموزش دادهایم. این ویدیو بخشی کوتاه از کارگاه آموزش گوگل سرچ کنسول است که در آن همه بخشها و مفاهیم کاربردی در این ابزار قدرتمند را آموزش دادهایم.
گام آخر؛ تست آنلاین عملکرد فایل robots.txt
گاهی اوقات دستوراتی که در فایل robots.txt استفاده میکنیم شامل شرطهای تودرتو و پیچیدهای هستند. اطمینان از عملکرد صحیح این فایل اهمیت زیادی برای ما دارد چراکه ممکن است به اشتباه صفحاتی را از دسترس گوگل خارج کرده باشیم. خوشبختانه گوگل فکر خوبی برای رفع این مشکل کرده است؛ ابزار آنلاین تست فایل robots.txt در گوگل سرچ کنسول.
در بخش coverage لینک به این ابزار را مشاهده میکنیم و لی در حال حاضر دسترسی به این ابزار به صورت مستقیم و از منوهای گوگل سرچ کنسول وجود ندارد. برای دسترسی میتوانیم از لینک مستقیم ابزار تست آنلاین robots.txt استفاده کنیم.
نحوه استفاده از این ابزار پیچیده نیست و به صورت کامل در ویدیوی 5 دقیقهای زیر توضیح داده شده است. نکتهای که هنگام استفاده از آن باید در نظر داشته باشیم این است که تغییرات ما در این ابزار بر روی سایت اعمال نخواهد شد و آنچه مشاهده میکنیم به صورت کامل در یک فضای نمونه و شبیهسازی شده رخ میدهد. هر تغییری که در محتوای فایل ایجاد میکنیم را باید در نهایت به نسخه آنلاین فایل در سایت خود اضافه کنیم.
وقتی گوگل به حرف دستورات ما اهمیتی نمیدهد!
احتمالاً با دیدن این تیتر تعجب کردهاید. تجربه نشان داده که گوگل پایبند الزامی برای توجه به دستورات فایل Robots.txt ندارد. گاهی اوقات ما دسترسی یک صفحه از سایت با استفاده از دستور Disallow میبندیم اما در کمال تعجب صفحه یا صفحات مسدود شده، ایندکس و حتی در نتایج جستجو نمایش داده میشوند.
اگر یک صفحه از صفحات داخلی و خارجی زیاد لینک دریافت کند یا از نظر گوگل محتوای ارائه شده در صفحه ارزشمند و اختصاصی باشد ممکن است آن را ایندکس کرده و حتی در نتایج جستجو نشان دهد. بهترین راه برای اطمینان از ایندکس نشدن یک صفحه، قرار دادن کد Noindex در هدر صفحه است.
<meta name=”robots” content=”noindex,nofollow”/>
البته این حرف ما نیست، بلکه جان مولر، متخصص و تحلیل گر وب مستر در گوگل این موضوع را به صورت شفاف اعلام کرده است.
ما در صفحه نکات سئو از زبان گوگل، مجموعهای از مهمترین صحبتها، توییتها و اخباری که جان مولر در چند سال اخیر به صورت عمومی منتشر کرده است را جمعآوری کردهایم. پیشنهاد میکنیم با مراجعه به این صفحه مهمترین نکات سئو را از زبان خود گوگل یاد بگیرید!
بررسی فایل Robots.txt در دیجی کالا و آپارات
چند خط کد ساده و نجات سایتهای بزرگ ایرانی! هرچهقدر ابعاد یک سایت بزرگتر باشد، مدیریت بودجه خزش اهمیت بیشتری پیدا میکند. برای درک این موضوع، در این بخش از مقاله فایل Robots.txt دو سایت پربازدید و بزرگ ایرانی یعنی دیجیکالا و آپارات را بررسی میکنیم.
دیجی کالا؛ میلیونها صفحهای کمارزش خارج از دید گوگل
روزانه هزاران نفر به سایت دیجیکالا مراجعه میکنند. مشاهده محصولات، مقایسه کالاها و در نهایت انجام خریدهای مورد نیاز بخشی از مهمترین فرآیندهایی است که در این سایت انجام میشود. صدها دستهبندی و میلیونها صفحه در دیجی کالا وجود دارد. از طرف دیگر روزانه صدها محصول جدید هم به سایت اضافه میشود. مدیریت همه این صفحات کار دشواری است. بسیاری از این صفحات در استراتژی سئو دیجیکالا جایی ندارند و بههیچوجه نباید ایندکس شوند.
در حقیقت مدیریت بودجه خزش و استفاده صحیح از دستورالعملهای Robots.txt در دیجیکالا اهمیت دوچندانی دارد. تصویر زیر تنها بخش کوچکی از فایل Robots.txt دیجیکالا را نمایش میدهد. برخی از این دستورات را بررسی میکنیم:

دستور disallow: /card مربوط به سبد خرید است. با توجه به اینکه هنگام خرید محصول بسته به تعداد محصول یک URL یکتا ساخته میشود و روزانه صدها نفر از دیجیکالا خرید میکنند، این دسته صفحات به هیچ وجه نباید در دسترس گوگل باشند. گردش رباتها در این صفحات هیچ نتیجهای جز هدر رفتن بودجه خزش نخواهد داشت.
دیجیکالا دسترسی رباتهای گوگل به صفحه پرداخت را هم بسته است تا این صفحه که شامل اطلاعات شخصی و مالی کاربران است توسط گوگل ایندکس نشود.
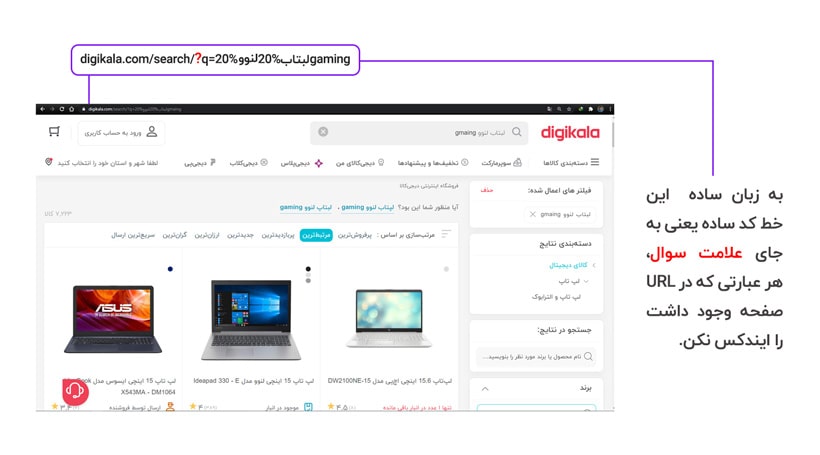
یکی دیگر از هوشمندیها و تصمیمات درست دیجیکالا استفاده از دستور disallow: *?* است. این دستور مربوط به بخش جستجو در داخل سایت است. به زبان ساده این خط کد ساده یعنی به جای علامت سوال، هر عبارتی که در URL صفحه وجود داشت را ایندکس نکن.
بسیاری از کاربران از طریق جستجو در داخل دیجیکالا محصول مورد نظر خود را انتخاب می کنند و هنگام جستجو یک URL مختص به همان جستجو ساخته میشود. با توجه به تعدد جستجوها که توسط کاربران مختلف صورت میگیرد، بایستی دسترسی ربات به این بخش بسته باشد تا بودجه خزش هدر نرود.
یکی دیگر از تصمیمات جالب دیجی کالا در Robots.txt، بستن دسترسی رباتها هنگام مقایسه محصولات است. هنگام مقایسه یک یا چند محصول یک URL یکتا ساخته میشود. با تغییر محصولات و انتخاب محصولات متنوع این URL تغییر میکند. میتوانیم حدس بزنیم که به صورت روزانه صدها هزار صفحه به این شکل ساخته میشود. طبیعتاً رباتها نباید زمان خود را صرف صفحاتی کنند که هیچ ارزش سئو برای دیجیکالا ندارند. با استفاده از دستور disallow: /compare/* دسترسی رباتها به این صفحات محدود شده است.
آپارات؛ تصمیمات هوشمندانه برای مدیریت درست بودجه خزش
آپارات روزانه میزبان میلیونها کاربر است که در این سایت به تماشای ویدیو میپردازند. تصویر زیر بخشی از Robots.txt آپارات را نشان میدهد:

آپارات دسترسی رباتهای گوگل به Sort کردن ویدیوها را بسته است. به عبارت دیگر در صفحات مختلف آپارات بر اساس معیارهایی مثل علاقه، زمان یا دیگر فاکتورها امکان مرتب سازی ویدیوها به صورت دلخواه وجود دارد. در این شرایط یک URL یکتا ساخته میشود. سایت آپارات با بستن دسترسی رباتهای گوگل به این تنظیمات که از هر کاربر به کاربر دیگر متفاوت است، از ایندکس شدن هزاران یا شاید میلیونها صفحه در گوگل جلوگیری کرده است.
در کارگاه آموزش سئو تکنیکال به صورت کامل استانداردهای کدنویسی و ساختار URL در صفحات وب را بررسی میکنیم. پیشنهاد میکنیم با شرکت در این کارگاه به صورت عمیق با سئو تکنیکال آشنا شوید.
استانداردهای سئو در طراحی و کدنویسیآموزش سئو تکنیکال
سایر دستورات موجو در فایل Robots آپارات بر اساس ساختار URL این سایت تعریف شده است. هنگام بررسی فایل Robots.txt آپارات یک مورد جالب و البته هوشمندانه هم به چشم میآید.
آپارت دسترسی رباتهای گوگل به پروفایل کاربران را بسته است. به عبارت دیگر اگر فردی در آپارت یک پروفایل داشته باشد، رباتهای گوگل امکان ایندکس صفحه اختصاصی او را نخواهند داشت. اما مساله اینجاست که برندهای زیادی در آپارات فعالیت میکنند. یکی از اهداف این برندها کسب ورودی از گوگل از طریق بازاریابی ویدیویی است.
با گذاشتن یک شرط کوچک دسترسی رباتها به صفحه پروفایل برندها بر خلاف کاربران باز است. به این ترتیب با مدیریت درست فایل Robots.txt هم از ایندکس میلیونها صفحه نامربوط و احتمالاً آزاردهنده جلوگیری شده است و هم برندهایی که از آپارات برای بازاریابی ویدیویی استفاده میکنند، شانس حضور در صفحه نتایج و جذب مخاطب را در اختیار دارند.
قوانین فقط برای رباتهای گوگل هستند؟ برای سایر ابزارها چه کار کنیم؟
دستورات موجود در فایل Robots.txt فقط مربوط به رباتهای گوگل نیست و میتوان دسترسی رباتهای مختلف را برای بررسی و آنالیز سایت مسدود کرد. کراولهای زیادی با اهداف مختلف در حال ایندکس صفحات وب هستند. خبرخوانها و رباتهای آنالیز سایتهای «Moz» و«Ahrefs» از جلمه این رباتها هستند. برخی از متخصصان سئو بر این باور هستند که مسدود کردن دسترسی این رباتها تاثیر مثبتی بر روی سئو سایت دارد.
این ادعا را از دو وجه میتوان بررسی کرد. با بستن دسترسی رباتهای مختلف مثل رباتهای آنالیز و تحلیل صفحات، رقبا نمیتوانند به اطلاعات سایت ما دسترسی داشته باشند. نکته دوم این است که بستن دسترسی باعث صرفه جویی در منابع زیرساختی سایت مثل مصرف CPU و پهنای باند میشود.
بستن دسترسی رباتها با هدف جلوگیری از تحلیل و آنالیز صفحات توسط رقبا، استراتژی چندان رایجی نیست. دقت داشته باشید که برای مثال اگر شما دسترسی رباتهای «Ahrefs» را به سایت خود ببندید، موجب میشود تا لینکهایی که از سایت شما به بیرون داده شده در دسترس ابزار نباشد ولی همچنان فعالیتهای شما در لینکسازی خارجی قابل تحلیل است چرا که دسترسی ابزار Ahrefs به سایر سایتها مسدود نشده است.
صرفه جویی در مصرف منابع هم تنها برای سایتهای بزرگ کارآمد است. در سایتهای کوچک و متوسط، کروال روزانه تاثیر زیادی در مصرف منابع ندارد. بنابراین بستن دسترسی رباتها به صفحات سایت شما کاملاً به اهداف، استراتژی سئو و میزان بزرگی سایت شما بستگی دارد. نمیتوان در این خصوص نظر قطعی داد. نکته جالب اینجاست که حتی با بستن دسترسی رباتهای مختلف، امکان بررسی سایت شما وجود دارد.
دستورات Robots.txt برای تمامی رباتهایی که به پروتکلهای وب پایبند هستند، الزامی است. دقت داشته باشید که رباتها بایستی به پروتکلها وب پایبند باشند تا از ایندکس صفحات جلوگیری شود. اجازه دهید با یک مثال این موضوع را بررسی کنیم. قوانین راهنمایی و رانندگی تا وقتی اعتبار دارند که به آن عمل کنیم. برای مثال بسیاری از رانندگان متاسفانه قوانین راهنمایی و رانندگی را نادیده گرفته و وارد خیابان ورود ممنوع میشوند. این مساله در فضای وب هم رایج است. رباتهای زیادی وجود دارند به پروتکلهای وب پایبند نیستند و اقدام به اینکدس صفحات میکنند.
برخی از وبمستران برای بستن دسترسی این رباتهای قانون شکن از تکنیکهایی مثل کدنویسی در سمت سرور استفاده میکنند. در این تکنیک، آی پی سرور ربات مورد نظر شناسایی و دسترسی این آی پی به سایت مسدود میشود.
فایل Robots.txt تنها ابزار مدیریت بودجه خزش نیست
در این مقاله به صورت کامل فایل Robots.txt را در قالب مثالهای مختلف بررسی کنیم. ابتدا Robots.txt و اهمیت آن در سئو را بررسی کردیم و سپس به سراغ ساخت این فایل رفتیم. در انتها هم فایل Robots.txt دو سایت بزرگ ایرانی؛ دیجیکالا و آپارات را بررسی کردیم. اما باید به یک نکته مهم دقت داشته باشید.
فایل Robots.txt تنها ابزار مدیریت بودجه خزش نیست. در حقیقت این فایل یک تکه کوچک از پازل ابزارها و دانشی است که میتواند به مدیریت بودجه خزش کمک کند. استفاده از تگ کنونیکال، ریدایرکت 301 و ساخت نقشه سایت قطعات دیگری هستند پازل مدیریت بودجه خزش را تکمیل میکنند. پیشنهاد میکنیم با خواندن مقالات زیر بودجه خزش سایت خود را به بهترین شکل مدیریت کنید.
در پایان از شما میخواهیم اگر سوال یا ابهامی در خصوص فایل Robots.txt دارید، در زیر همین صفحه پرسش خود را مطرح کنید. سوالات، نظرات و تجربیات شما برای ما و مخاطبان آکادمی وبسیما ارزشمند است.
رایجترین سوالات در مورد فایل robots.txt
خیر، این فایل با هدف ایجاد محدودیت دسترسی برای رباتهای گوگل ساخته میشود. در بسیاری از سایتها بهویژه آنهایی که تعداد صفحاتشان محدود است نیازی به این فایل نداریم.
استفاده از این فایل تنها زمانی کاربرد دارد که دلیلی برای محدود کردن دسترسی گوگل به بخشی از سایت داشته باشیم.
احتمالا سوال شما این است که داشتن یا نداشتن این فایل چقدر بر سئو سایت ما تاثیرگذار است؟
اگر از منظر تکنیکال این سوال را بررسی کنیم میتوان گفت که ساخت این فایل هیچ تاثیر مستقیمی بر رتبهبندی صفحات وب ندارد ولی تصور کنید که به واسطه آن دسترسی گوگل به یک صفحه مهم و ارزشمند از سایت ما مسدود شده باشد.
در این شرایط رباتهای گوگل قادر به ایندکس صفحه مورد نظر نبوده و در نتیجه شانسی برای حضور و کسب جایگاه در نتایج جستجو نداریم.
مسدود کردن یک صفحه در فایل Robots.txt در واقع یک پیشنهاد از طرف ما به رباتهای گوگل بوده و هیچ الزامی برای پیروی از آن وجود ندارد. سیگنالهای متعددی برای ایندکس یک صفحه توسط گوگل وجود دارد.
به عنوان مثال اگر صفحه مورد نظر محتوایی اختصاصی و ارزشمند داشته باشد، آدرس آن در نقشه سایت ما درج شده باشد و لینکسازیهای داخلی و خارجی زیادی برای آن انجام شده باشد؛ ممکن است گوگل دستورات این فایل را نادیده گرفته و صفحه مورد نظر را ایندکس کند.
ایمنترین راه برای جلوگیری از ایندکس استفاده از ویژگی noindex در تگ متا و head صفحه است.
دستوراتی که در این فایل درج میکنیم یک زبان مشترک و پروتکل جهانی برای مدیریت منابع و محدود کردن دسترسی رباتهای خزنده به سایت است. ابزارهای متعددی در سطح وب وجود دارند که به محتوای این فایل احترام گذاشته و در صورت مسدود بودن دسترسی صفحات ما را خزش نمیکنند. ولی فرامووش نکنیم که بسیاری از ابزارها (مثلا آنهایی که کارشان کپی کردن محتوای سایت است) به این فایل بیتوجه بودن و عملکرد خود را به آن وابسته نمیکنند.
فایل robots.txt یکی از آدرسهای مهم سایت ما بوده و رباتهای گوگل به صورت مستمر آن را بررسی میکنند.
در صورتیکه تغییراتی اساسی و مهم در محتوای آن ایجاد کردهایم بهتر است از طریق ابزار robots.txt tester که در سرچ کنسول وجود دارد این تغییرات را به گوگل اطلاعرسانی کنیم تا در سریعترین زمان ممکن بررسی شده و در سایت اجرایی گردد.

امین اسماعیلی هستم، فارغ التحصیل مقطع کارشناسی ارشد از دانشگاه تهران و مدیر فنی آژانس خلاقیت وبسیما. از سال 91 تمرکز خود را بر روی مباحث روز سئو و طراحی سایت قرار داده و پس از کسب تجربه و دانش ارزشمند تصمیم گرفتم تا ثمره آن را با دیگران به اشتراک بگذارم.

سئو تکنیکال






